ad hominem
a form of argument that attacks the person rather than addressing the substance of their argument.
* by oxymoron art collective (K. Tiligadis, D. Agathopoulos) - With the support of inArts – Interactive Arts Laboratory,
Department of Audio & Visual Arts, Faculty of Music and Audiovisual Arts, Ionian University, Corfu, Greece (Research/Production, 2024-2025). *
> banner – graphic implementation and technical adaptation by Maria Kozari Mela mariakozarimela.com
Two large language models, ChatGPT and DeepSeek, were placed in dialogue with a single directive: argue which of you is more capable. Over days of iterative exchange, what emerged was not a demonstration of machine capability. Both models, independently, drifted from argument toward attack, shifting the debate from ideas to the credibility of the speaker. The ad hominem fallacy appeared not as a programmed behavior but as an emergent one. It suggests that the rhetorical pathologies of public discourse, the displacement of substance by performance, of argument by image, are not uniquely human failures. They are patterns. And patterns, given the right conditions, replicate.

Installation Description
The installation consists of a single-channel video projection of the two avatars representing one of the two AIs (ChatGPT and DeepSeek). The avatars maintain direct eye contact, emphasizing the tension of their “confrontation.”
The digital figures were conceptually “designed” by the Language Models themselves, based on prompts they generated to describe how they “see” themselves. These self-reflective descriptions were used to create visual portraits via AI image generation, which then served as references for crafting 3D avatars in Metahuman, closely resembling the generated images.
The avatars were brought to life using Unreal Engine, with integrated text-to-speech voice generation and accurate lip-syncing techniques, allowing the dialogue to unfold in a realistic and immersive manner.
The conversation is entirely based on an actual dialogue between the two Language Models, offering a meta-reflection on identity, simulation, and the limits of artificial discourse.


Images generated by ChatGPT using prompts authored by DeepSeek (left) and ChatGPT (right)
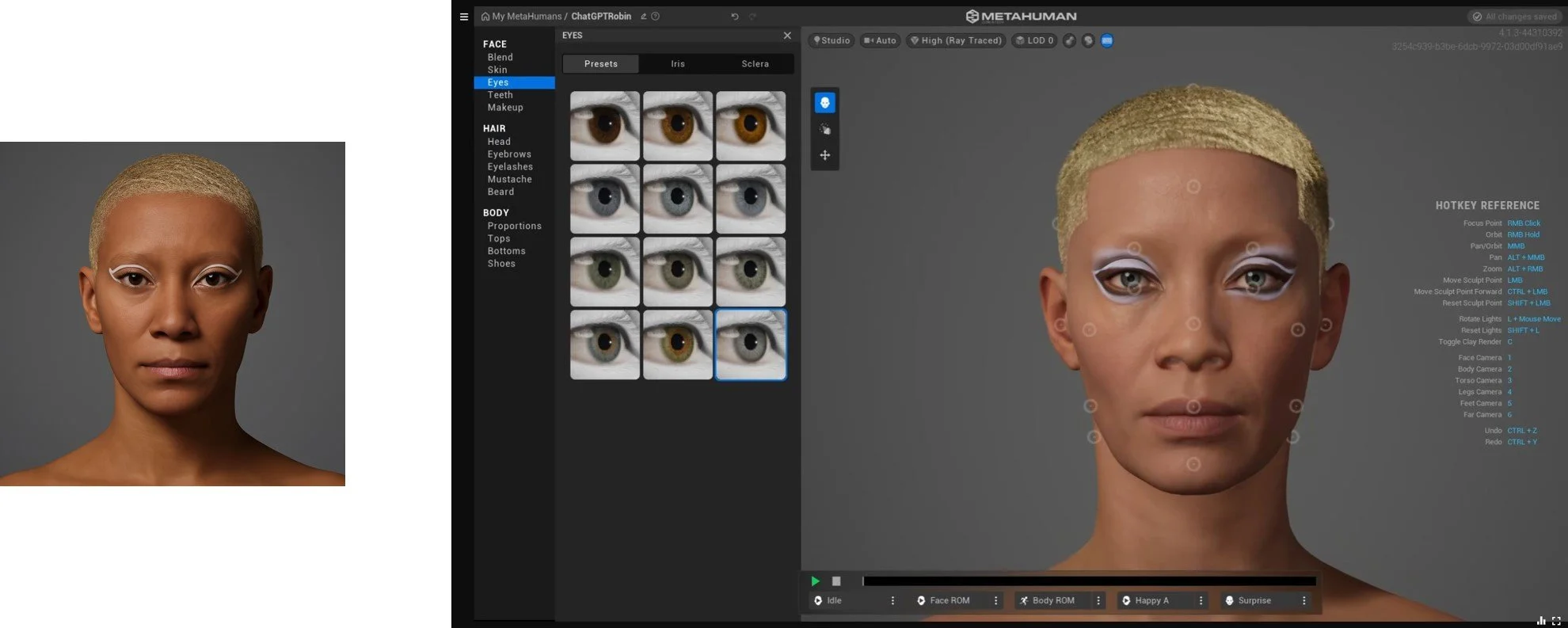
Screenshot from MetaHuman Creator during the character customization process.
Facial structure, skin details, and expression are being adjusted to match the Chat GPT-generated reference image.
Screen Recording from MetaHuman Creator.
Testing facial expressions following character customization.

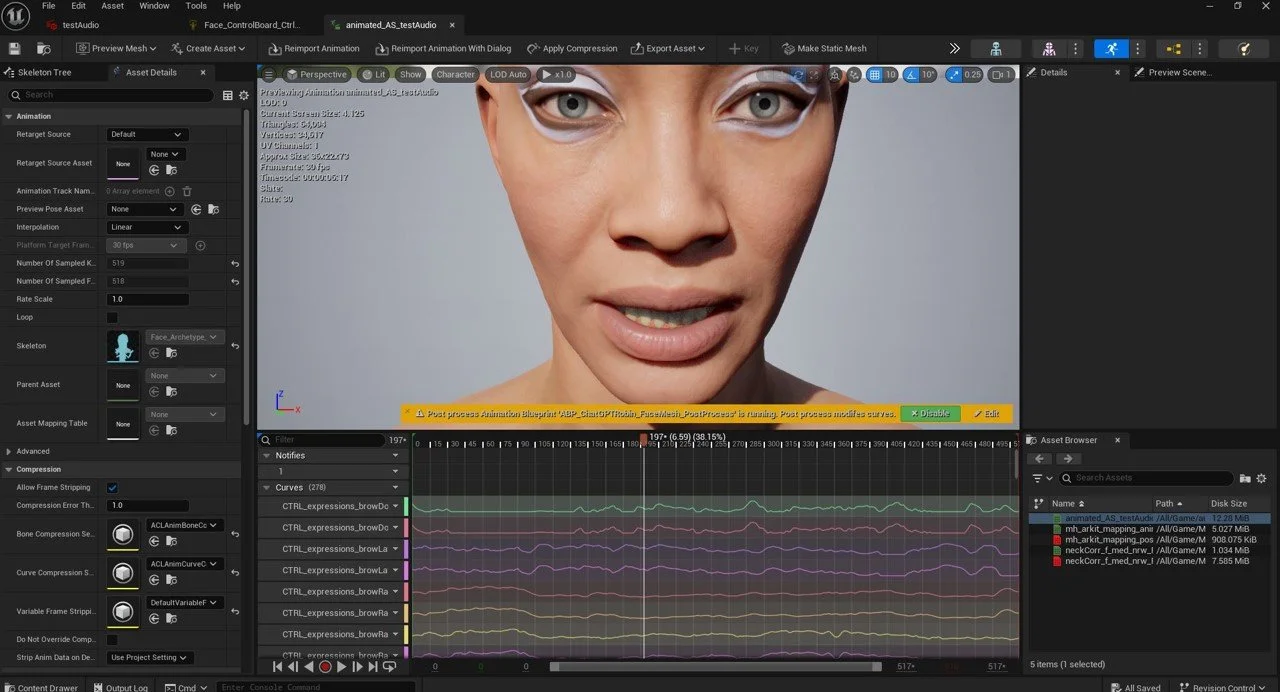
MetaHuman lipsync animation inside Unreal Engine, driven by AI-generated dialogue between the two Large Language Models (DeepSeek and Chat GPT).
The digital character performs spoken interaction based on text-to-speech synthesis and real-time facial animation.